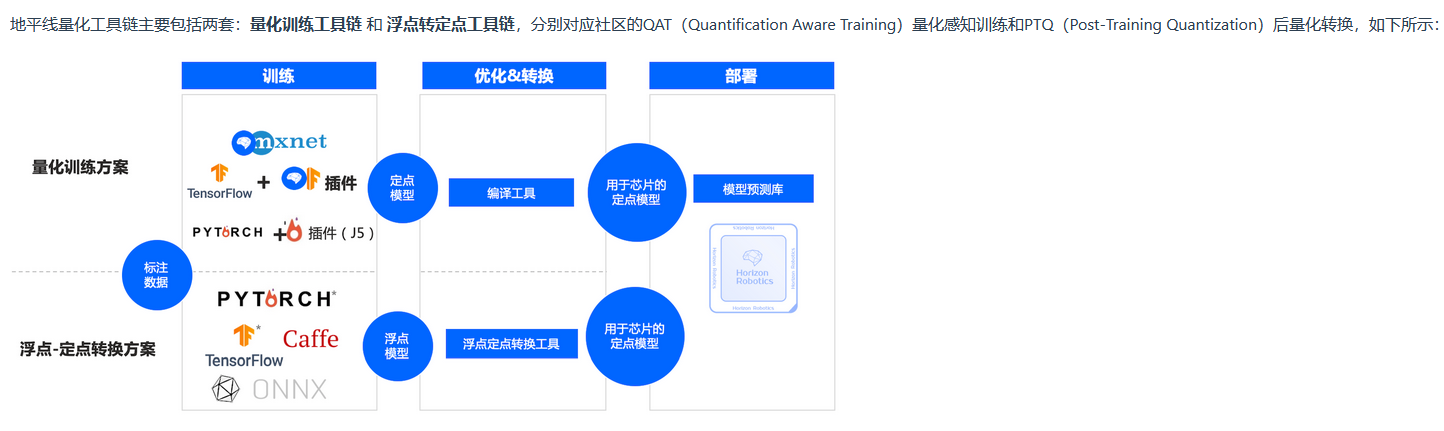
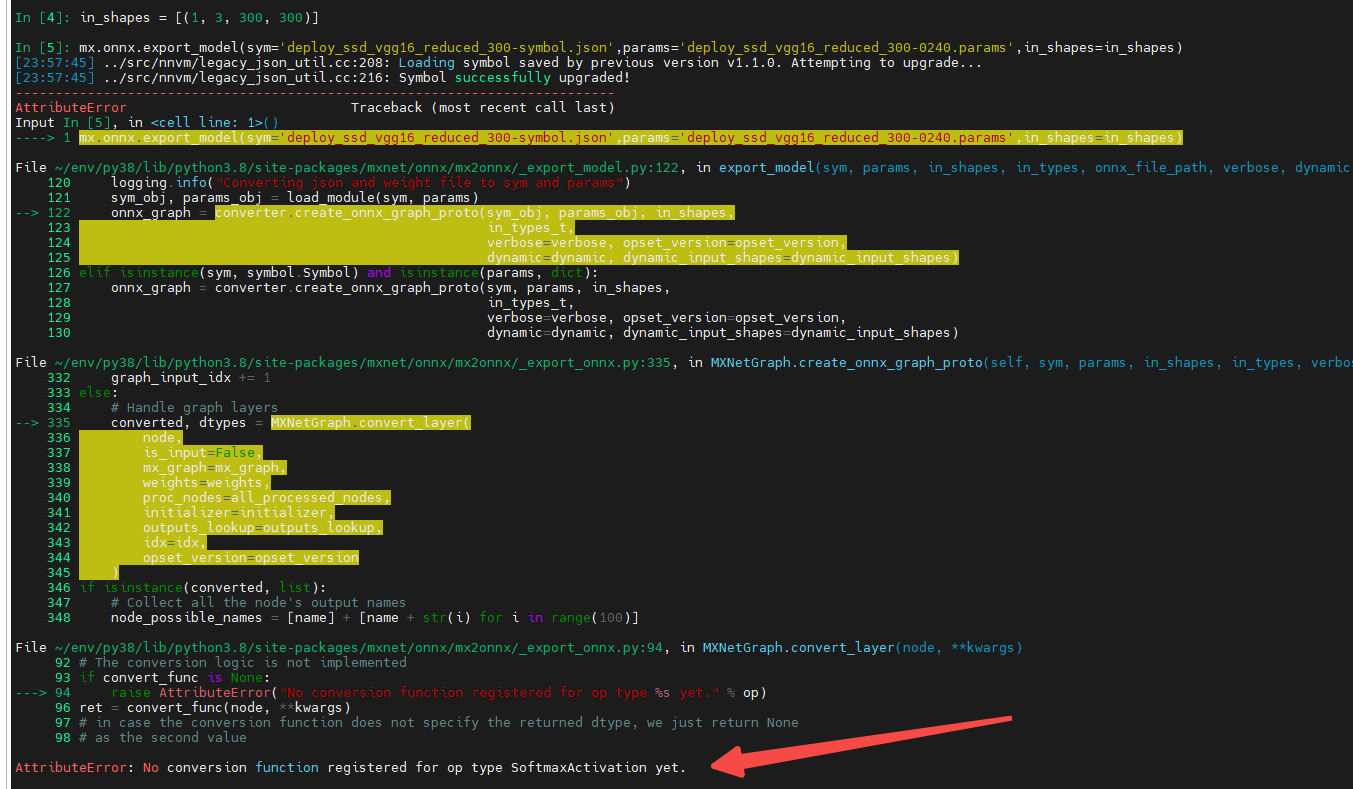
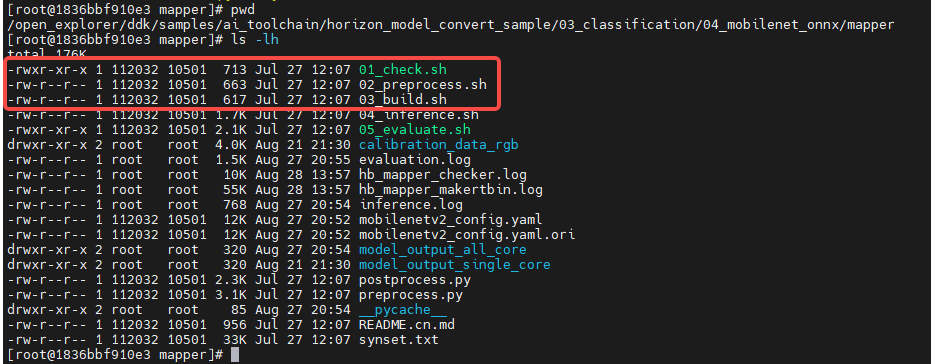
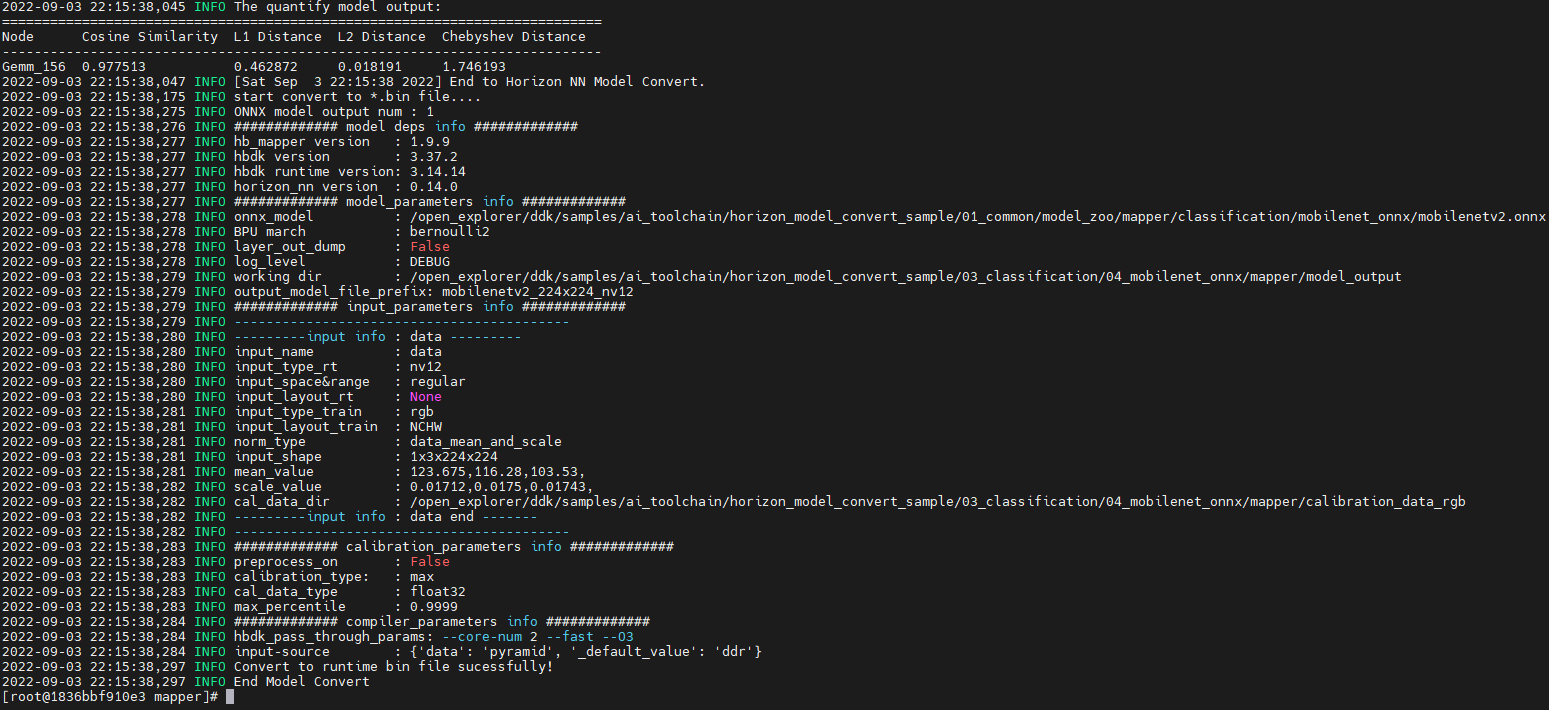
#include <stdio.h>
// Path for c_predict_api
#include <mxnet/c_predict_api.h>
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <opencv2/opencv.hpp>
const mx_float DEFAULT_MEAN = 117.0;
// Read file to buffer
class BufferFile {
public :
std::string file_path_;
int length_;
char* buffer_;
explicit BufferFile(std::string file_path)
:file_path_(file_path) {
std::ifstream ifs(file_path.c_str(), std::ios::in | std::ios::binary);
if (!ifs) {
std::cerr << "Can't open the file. Please check " << file_path << ". \n";
length_ = 0;
buffer_ = NULL;
return;
}
ifs.seekg(0, std::ios::end);
length_ = ifs.tellg();
ifs.seekg(0, std::ios::beg);
std::cout << file_path.c_str() << " ... "<< length_ << " bytes\n";
buffer_ = new char[sizeof(char) * length_];
ifs.read(buffer_, length_);
ifs.close();
}
int GetLength() {
return length_;
}
char* GetBuffer() {
return buffer_;
}
~BufferFile() {
if (buffer_) {
delete[] buffer_;
buffer_ = NULL;
}
}
};
void GetImageFile(const std::string image_file,
mx_float* image_data, const int channels,
const cv::Size resize_size, const mx_float* mean_data = nullptr) {
// Read all kinds of file into a BGR color 3 channels image
cv::Mat im_ori = cv::imread(image_file, cv::IMREAD_COLOR);
if (im_ori.empty()) {
std::cerr << "Can't open the image. Please check " << image_file << ". \n";
assert(false);
}
cv::Mat im;
cv::resize(im_ori, im, resize_size);
float mean_b, mean_g, mean_r;
mean_b = 104.0;
mean_g = 117.0;
mean_r = 123.0;
for(int i=0; i < im.rows; ++i){
uchar* data = im.ptr<uchar>(i);
for(int j=0; j< im.cols; ++j){
image_data[2*im.rows*im.cols+i*im.cols+j] = static_cast<mx_float>(*data++) - mean_b;
image_data[im.rows*im.cols+i*im.cols+j] = static_cast<mx_float>(*data++) - mean_g;
image_data[i*im.cols+j] = static_cast<mx_float>(*data++) - mean_r;
}
}
}
int main(int argc, char* argv[]) {
if (argc < 4) {
std::cout << "Usage: ./detect symbol_path params_path image_path" << std::endl;
return 0;
}
std::string test_file;
test_file = std::string(argv[3]);
// Models path for your model, you have to modify it
std::string json_file = std::string(argv[1]);
std::string param_file = std::string(argv[2]);
BufferFile json_data(json_file);
BufferFile param_data(param_file);
// Parameters
int dev_type = 1; // 1: cpu, 2: gpu
int dev_id = 0; // arbitrary.
mx_uint num_input_nodes = 1; // 1 for feedforward
const char* input_key[1] = {"data"};
const char** input_keys = input_key;
// Image size and channels
int width = 512;
int height = 512;
int channels = 3;
const mx_uint input_shape_indptr[2] = { 0, 4 };
const mx_uint input_shape_data[4] = { 1, static_cast<mx_uint>(channels), static_cast<mx_uint>(height), static_cast<mx_uint>(width)};
PredictorHandle pred_hnd = 0;
if (json_data.GetLength() == 0 || param_data.GetLength() == 0) {
return -1;
}
// Create Predictor
MXPredCreate((const char*)json_data.GetBuffer(),
(const char*)param_data.GetBuffer(),
static_cast<size_t>(param_data.GetLength()),
dev_type, dev_id, num_input_nodes, input_keys, input_shape_indptr, input_shape_data, &pred_hnd);
assert(pred_hnd);
int image_size = width * height * channels;
// // Read Image Data
std::vector<mx_float> image_data = std::vector<mx_float>(image_size);
GetImageFile(test_file, image_data.data(), channels, cv::Size(width, height));
// // Set Input Image
int64 start = cv::getTickCount();
MXPredSetInput(pred_hnd, "data", image_data.data(), image_size);
// // Do Predict Forward
MXPredForward(pred_hnd);
mx_uint output_index = 0;
mx_uint *shape = 0;
mx_uint shape_len;
// Get Output Result
MXPredGetOutputShape(pred_hnd, output_index, &shape, &shape_len);
size_t size = 1;
for (mx_uint i = 0; i < shape_len; ++i) size *= shape[i];
std::vector<float> data(size);
MXPredGetOutput(pred_hnd, 0, data.data(), size);
int64 end = cv::getTickCount();
double secs = (end-start)/cv::getTickFrequency();
std::cout<<"time: " <<secs<<std::endl;
assert(data.size() % 6 == 0);
cv::Mat mat = cv::imread(test_file, 1);
int orig_cols = mat.cols;
int orig_rows = mat.rows;
cv::resize(mat, mat, cv::Size(width, height));
for(int i=0; i<data.size(); i+=6){
if(data[i]<0) continue;
int id = static_cast<int>(data[i]);
float score = data[i+1];
if(score < 0.5) continue;
std::cout<<score<<std::endl;
int xmin = static_cast<int>((data[i+2])*width);
int ymin = static_cast<int>((data[i+3])*height);
int xmax = static_cast<int>((data[i+4])*width);
int ymax = static_cast<int>((data[i+5])*height);
cv::rectangle(mat, cv::Point(xmin, ymin), cv::Point(xmax, ymax), cv::Scalar(255, 0, 0), 2);
}
cv::resize(mat, mat, cv::Size(orig_cols, orig_rows));
cv::imshow(test_file, mat);
cv::waitKey(0);
return 0;
}